캐시 메모리(Cache Memory)란?
어떤 프로그램을 동작시키기 위해서는 메모리에 적재가 되고 CPU를 할당받아야 동작이 된다. 이때 CPU와 메모리(RAM) 사이에서 활발하게 데이터를 주고받게 되는데 CPU에 비해 비교적 속도가 느린 메모리에 의해서 제대로 성능을 내지 못한다.
캐시 메모리는 CPU와 RAM 사이에서 발생하는 병목 현상을 완화하고자 사용된다.
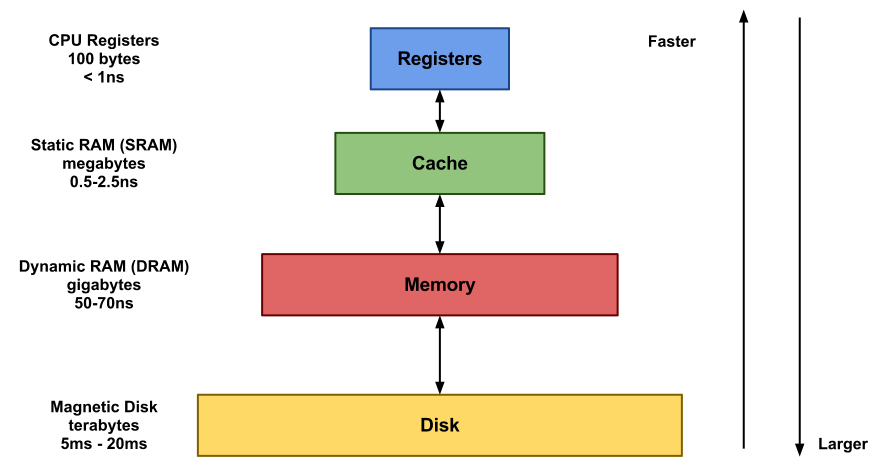
캐시 메모리는 CPU 사이에 존재하며 캐시 메모리에 데이터가 존재한다면 메모리에 접근할 필요가 없으므로 성능상 이점을 얻을 수 있다.
적중 & 실패
CPU는 메모리에 접근하기 전에 캐시 메모리를 먼저 들러 찾고자 하는 데이터가 있는지 확인한다.
- 필요한 데이터를 찾았을 때 : 적중(Cache Hit)
- 필요한 데이터를 찾지 못했을 때 : 실패(Cache Miss)
요청한 데이터를 캐시 메모리에서 찾을 확률을 캐시 적중률(cache hit ratio)이라고 하며 캐시 메모리의 성능은 적중률에 의해 결정된다.
적중률 = 캐시 메모리의 적중 횟수 / 전체 메모리의 참조 횟수
CPU는 데이터를 가져오기 위해서 캐시 메모리 > 주기억장치(Memory) > 보조기억장치(Disk) 순으로 접근한다.
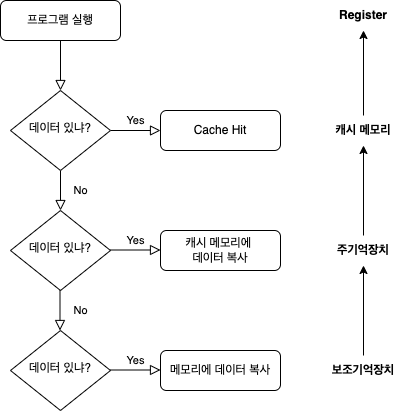
- Cache Hit 할 경우 : 캐시 메모리에서 데이터를 CPU 레지스터에 복사한다.
- Cache Miss & 메모리에서 찾았을 경우 : 메모리의 데이터를 캐시 메모리에 복사하고, 캐시 메모리에 복제된 내용을 CPU 레지스터에 복사한다.
- Cache Miss & 메모리에서 찾지 못했을 경우 : 보조기억장치에서 메모리에 적재하고 적재된 내용을 캐시 메모리에 복사한다. 그리고 캐시 메모리의 데이터를 CPU 레지스터에 복사한다.
공간 지역성 & 시간 지역성
캐시 메모리에 최대한 많은 데이터를 넣으면 좋은 성능을 낼 수 있겠지만 그게 가능했다면 주기억장치와 같은 저장 매체는 필요로 하지도 않았을 것이다. 담을 수 있는 데이터는 많지 않기 때문에 자주 사용될 것 같은 데이터를 담는 것이 좋다. 이때 사용하는 것이 지역성(locality)이다.
지역성에는 세 가지가 존재한다.
- 시간적 지역성 : 사용되었던 데이터가 가까운 시일 내에 한 번 더 사용될 가능성이 큰 성질
- 공간적 지역성 : 사용되었던 데이터의 인접 데이터가 사용될 가능성이 큰 성질
- 순차적 지역성 : 분기가 발생하지 않는 이상 순차적으로 실행될 가능성이 큰 성질
예제
10000 * 10000의 크기를 가지는 2차원 배열을 가지고 테스트해보려고 한다. 위에는 연속적인 데이터를 참조하는 것이고 밑에는 연속적이지 않은 데이터를 참조하여 걸리는 시간을 계산하는 소스이다.
반복문 내에 있으므로 시간 지역성을 가지며 이 둘의 차이점은 연속적인 공간을 참조하냐 안 하냐이다. 위 소스만 공간 지역성의 이점을 얻을 수 있어 위 소스가 빠른 결과를 나타낸다.
import time
N = 10000
arr = [[i] * N for i in range(N)]
start = time.time()
for i in range(N):
for j in range(N):
arr[i][j]
print(time.time() - start)
start = time.time()
for i in range(N):
for j in range(N):
arr[j][i]
print(time.time() - start)