Consistent Hashing은 대규모 분산 시스템에서 데이터를 균일하게 분산시키는 기술로 각 객체와 서버를 원형의 해시 공간에 배치하는 방식이다.
서버 간 데이터를 최대한 균등하게 배포하는 일반적인 방법은 단순 해싱 방식이다. 각 객체에 대해 Md5와 같은 해싱 함수를 이용하여 키를 해시하고 서버 수에 따라 모듈러 연산을 수행한다. 이렇게 생성된 객체 키는 항상 동일한 서버에 매핑된다.
serverIndex = hash{key} % N
where N is the size of the server pool
그러나 이 방식은 클러스터 수가 달라지게 되면 해시값이 같더라도 키들이 다른 서버랑 매핑되게 될 것이다. 이것은 서버의 추가나 제거 시에 문제가 발생한다. 새로운 서버가 추가되면 기존 객체들이 새로운 서버로 재배치되어야 하며 기존 서버가 제거되면 그 서버에 속한 객체들이 다른 서버로 이동해야 한다. 이 과정에서 대부분의 객체가 이동하게 되어 시스템 전체적인 안정성에 영향을 미치게 된다.
이런 문제를 해결하기 위해 Consistent Hashing 기법이 등장하였고 해당 기법은 서버의 추가나 제거 시에 대부분의 객체 이동을 최소화하여 시스템의 안정성을 높이는 방법을 제공한다.
동작 원리
동일한 해시 함수를 이용하여 모든 객체와 서버를 원형으로 동일한 해시 공간상에 위치시킨다. 특정 서버를 찾으려면 서버를 찾을 때까지 링의 키 위치에서 시계 방향으로 이동한다.
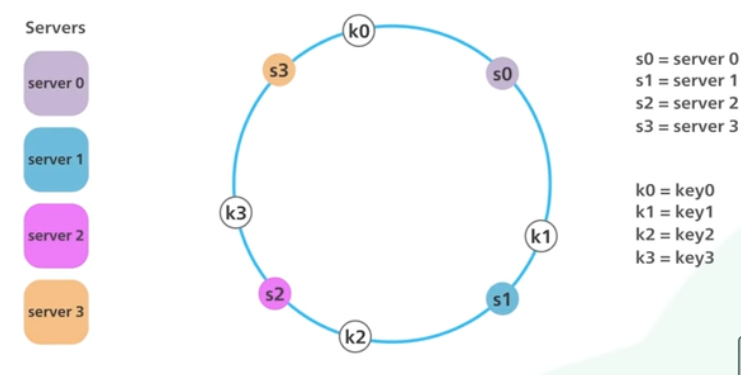
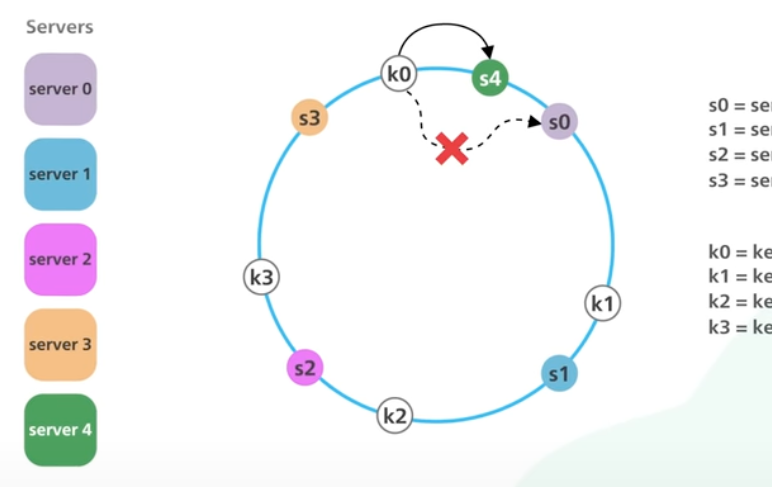
만약 서버가 추가된다면 k0로만 s0에서 s4로 이동하면 된다. 이렇게 되면 k1, k2, k3는 영향을 받지 않게 된다.
이렇기 때문에 simple hashing은 서버 추가 시 모든 키를 다시 매핑해야하는 반면 consistent hashing은 일부 키만 재분배하면 된다.
하지만 이런 디자인에 잠재적인 문제가 있는데 그것은 링 위에 서버의 분포가 고르지 않을 수 있다는 것이다. 링을 동일한 크기의 조각으로 완벽하게 분할하는 것은 불가능하다.
아래와 같이 매핑이 될 경우 대부분의 객체는 s2에 저장되고 나머지에는 데이터가 저장되지 않는다.
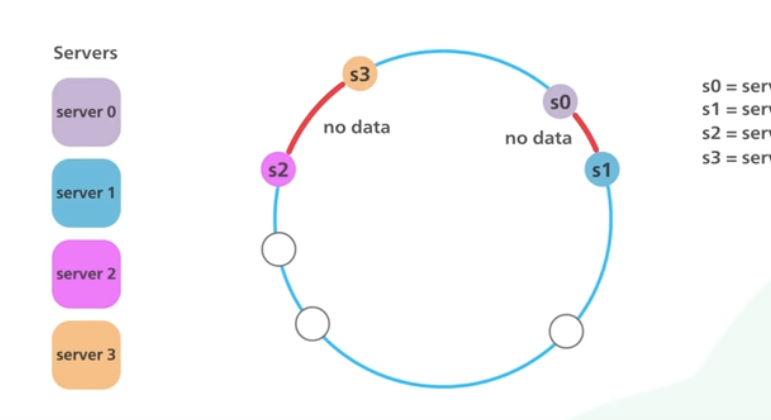
이러한 문제의 해결책으로 가상 노드를 사용한다. 각 서버는 여러 개의 가상 노드를 만들어내고 각 서버가 링에서 여러 구간을 처리하는 것이다.
결과로 가상 노드가 증가하게 되면서 객체의 분배가 더욱 균형 있게 이루어진다.
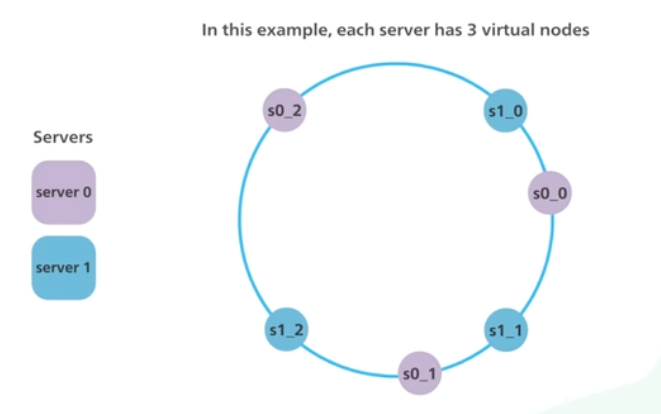

하지만 이것도 단점이 있는데 가상 노드가 많다는 것은 가상 노드에 대한 메타 데이터를 저장하는데 많은 공간을 사용한다는 것이다. trade-off 관계이며 요구 사항에 맞게 가상 노드 수를 조정해야 할 것이다.