slow query 원인을 확인해 보니 인덱스가 없어서 풀스캔이 발생하고 있었고, 인덱스 추가로 성능이 크게 개선됐다.
핵심은 단순하다.
- 조건으로 자주 거는 컬럼에 인덱스가 없으면 DB는 테이블을 처음부터 끝까지 훑어야 한다.
- 인덱스가 있으면 필요한 범위만 바로 점프해서 읽고(Index Lookup) 필요한 행만 가져온다.
문제 상황
다음 쿼리가 느렸다.
EXPLAIN ANALYZE
select *
from introduced_user_profile iup1_0
where iup1_0.user_introduce_group_id = 500
and iup1_0.is_active = true;
조건은 단순한데, 테이블 크기가 커지면서 응답이 버벅였고 실행계획을 보니 인덱스가 없어서 풀스캔을 하고 있었다.
실행계획 (인덱스 없을 때)
아래는 인덱스 추가 전 결과다.
type=ALLkey=nullrows가 매우 큼
실행계획을 표로 풀면 대략 이런 의미다.
select_type: SIMPLE
table : iup1_0
type : ALL -- 풀스캔
possible_keys: (none)
key : (none)
rows : 861912 (estimate)
Extra : Using where
-> Filter: ((iup1_0.is_active = true) and (iup1_0.user_introduce_group_id = 500)) (cost=87835 rows=8619) (actual time=694..718 rows=2 loops=1)
-> Table scan on iup1_0 (cost=87835 rows=861918) (actual time=0.467..663 rows=854125 loops=1)
여기서 중요한 포인트는:
Table scan on iup1_0- 말 그대로 테이블을 쭉 읽는다.
actual time이~700ms수준- 조건에 맞는 데이터는 최종적으로
rows=2건인데도, 중간에 엄청 많이 읽고 버렸다는 뜻이다.
- 조건에 맞는 데이터는 최종적으로
해결: 인덱스 추가
CREATE INDEX idx_iup_user_introduce_group_id
ON introduced_user_profile (user_introduce_group_id);
실행계획 (인덱스 추가 후)
인덱스를 추가한 뒤 실행계획은 이렇게 바뀌었다.
type=refkey=idx_iup_user_introduce_group_idrows가 2로 줄어듦
마찬가지로 요약하면:
select_type: SIMPLE
table : iup1_0
type : ref
possible_keys: idx_iup_user_introduce_group_id
key : idx_iup_user_introduce_group_id
ref : const
rows : 2 (estimate)
Extra : Using where
-> Filter: (iup1_0.is_active = true) (cost=0.52 rows=0.2) (actual time=0.0351..0.0376 rows=2 loops=1)
-> Index lookup on iup1_0 using idx_iup_user_introduce_group_id (user_introduce_group_id=500) (cost=0.52 rows=2) (actual time=0.0336..0.0358 rows=2 loops=1)
핵심 변화:
Table scan->Index lookupactual time ~700ms->~0.03ms수준- 읽어야 하는 후보 row가
861k근처 ->2건으로 급감
적용 전/후 비교
위 실행계획의 변화를 그림으로 요약하면 아래처럼 바뀐다.
아래 이미지는 인덱스 적용 전/후를 Datadog 지표(예: request latency p95/p99)로 비교한 결과이다.
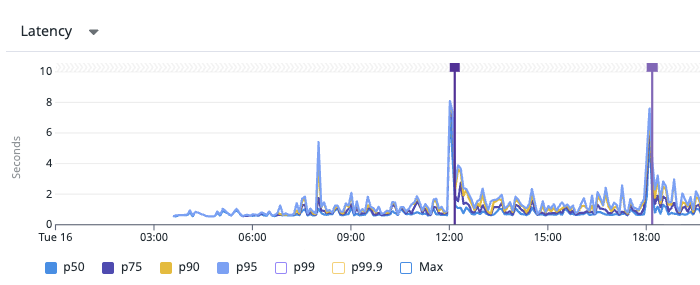
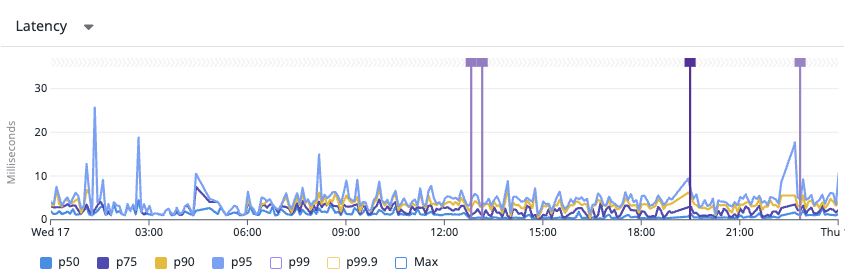
인덱스가 왜 이렇게 빠른가?
MySQL(InnoDB)에서 일반적인 보조 인덱스(secondary index)는 보통 B+Tree 구조다.
- 정렬된 트리 구조라서
- 특정 값(여기서는
user_introduce_group_id=500)을 찾을 때 - 처음부터 끝까지 훑는 게 아니라
- 트리 높이만큼만 내려가서(대략 log 스케일) 필요한 리프(leaf) 페이지로 점프한다.
- 특정 값(여기서는
추가로 InnoDB에서는 보조 인덱스의 리프에 PK(클러스터링 키) 가 같이 저장된다.
select *처럼 컬럼을 많이 가져오면- 보조 인덱스로 후보 row의 PK를 찾고
- 그 PK로 실제 레코드(클러스터드 인덱스)를 한 번 더 읽는 과정이 생길 수 있다.
- 반대로 조회 컬럼이 인덱스에 다 포함되면(covering index)
- 테이블을 다시 읽지 않고 인덱스만으로도 결과를 만들 수 있어 더 빨라질 때가 있다.
풀스캔이 “책을 1페이지부터 끝까지 넘기며 찾는 것”이라면, 인덱스 탐색은 “목차/색인을 보고 해당 페이지로 바로 가는 것”에 가깝다.
EXPLAIN에서 뭘 보면 되나
이번 케이스에서 특히 도움이 된 포인트는 아래였다.
typeALL: 테이블 풀스캔ref: 인덱스를 이용한 조회(동등 조건=등에서 자주 등장)
key/possible_keys- 실제로 어떤 인덱스를 탔는지, 혹은 탈 수 있었는지
rows- Optimizer가 예상하는 읽을 행 수(대략적인 비용 추정)
EXPLAIN ANALYZE의actual time,rows- “예상”이 아니라 실제 실행에서 얼마나 읽었는지 / 얼마나 걸렸는지
다음 단계: 더 좋은 인덱스가 있을까?
현재 쿼리 조건은 다음과 같다.
user_introduce_group_id = 500is_active = true
지금은 user_introduce_group_id로 먼저 후보를 좁히고, 그 결과에 대해 is_active를 추가 필터로 거는 형태다.
만약 user_introduce_group_id=500에 해당하는 row가 많고 그 중 is_active=true 비율이 낮아서 추가 필터링이 많이 발생한다면, 아래처럼 복합 인덱스가 더 유리할 수도 있다.
CREATE INDEX idx_iup_group_active
ON introduced_user_profile (user_introduce_group_id, is_active);
복합 인덱스가 유리한 전형적인 이유:
- 인덱스 자체에서 두 조건을 더 잘 반영해서
- 리프에서 꺼내오는 후보 row 수가 더 줄어든다.
다만 인덱스는 무조건 많이 만든다고 좋은 게 아니라:
- 쓰기 성능(INSERT/UPDATE/DELETE) 비용 증가
- 디스크/버퍼 사용량 증가
같은 트레이드오프가 있으니, 실제 트래픽 패턴과 쿼리 빈도를 보고 결정하는 게 안전하다.
정리
이번 케이스는 “인덱스가 왜 중요한지”를 너무 정직하게 보여줬다.
- 인덱스 없으면:
- 조건이 단순해도 풀스캔
- 읽어야 할 데이터가 커질수록 기하급수로 느려짐
- 인덱스 있으면:
- 필요한 곳으로 바로 찾아가서 최소한만 읽음
- 실행계획이
ALL->ref로 바뀌고,rows/actual time이 확 줄어듦