JDK21
Feature
- API 개선 및 확장
- 언어 개선 및 패턴 매칭
- 동시성 및 멀티스레딩
- 플랫폼 개선
API 개선 및 확장
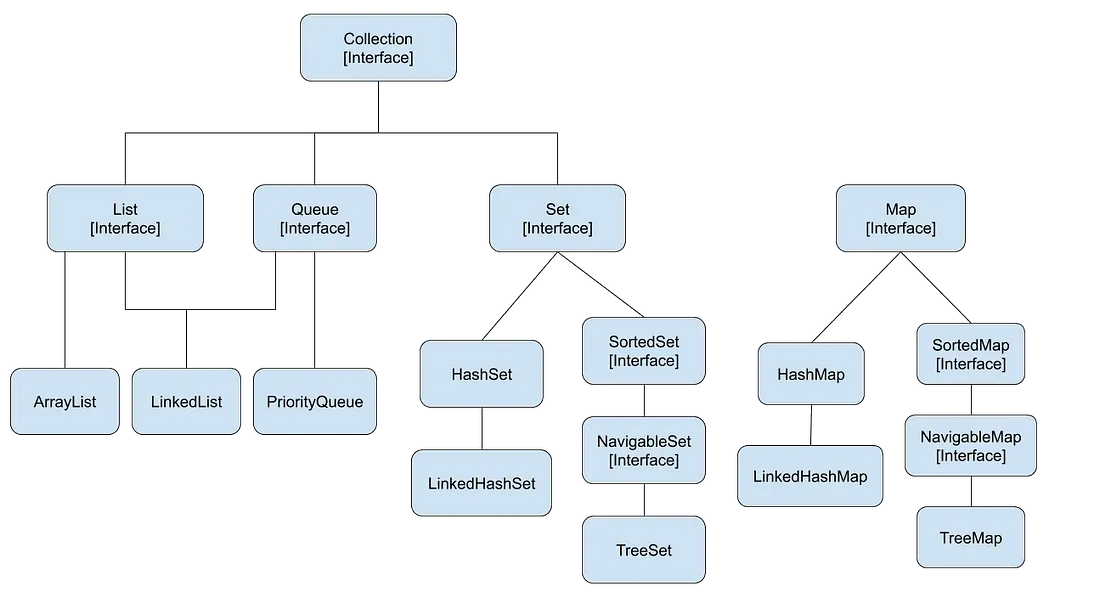
431: Sequenced Collections
자바 컬렉션 프레임워크에서 순서를 가지는 시퀀스를 표현하는 컬렉션 유형의 부재로 인하여 컬렉션에 대한 일관된 작업 세트의 부재 등 문제가 존재한다.
- List, Deque는 순서를 가지지만 그의 슈퍼타입인 컬렉션은 순서를 가지지 않는다.
- Set은 순서를 가지지 않고 그 하위 클래스인 HashSet도 순서를 가지지 않는다. 하지만 LinkedHashSet은 하위 타입을 가진다.
순서를 지원하는 것이 여러 계층에 분산되어 있어서 API에서 특정 유용한 개념을 표현하기 어렵게 한다.
| First element | Last element | |
| List | list.get(0) | list.get(list.size() - 1) |
| Deque | deque.getFirst() | deque.getLast() |
| SortedSet | sortedSet.first() | sortedSet.last() |
| LinkedHashSet | linkedHashSet.iterator().next() |
자바 컬렉션 프레임워크에서 순서를 가지는 시퀀스를 표현하는 컬렉션 유형 Sequenced Collections를 추가하였다.
Sequenced Collections는 요소들의 명시적인 순서를 가지는 컬렉션을 나타내며 컬렉션 프레임워크 내에서 요소의 순서를 명확하고 일관되게 표현할 수 있는 방법이 생겨났다.
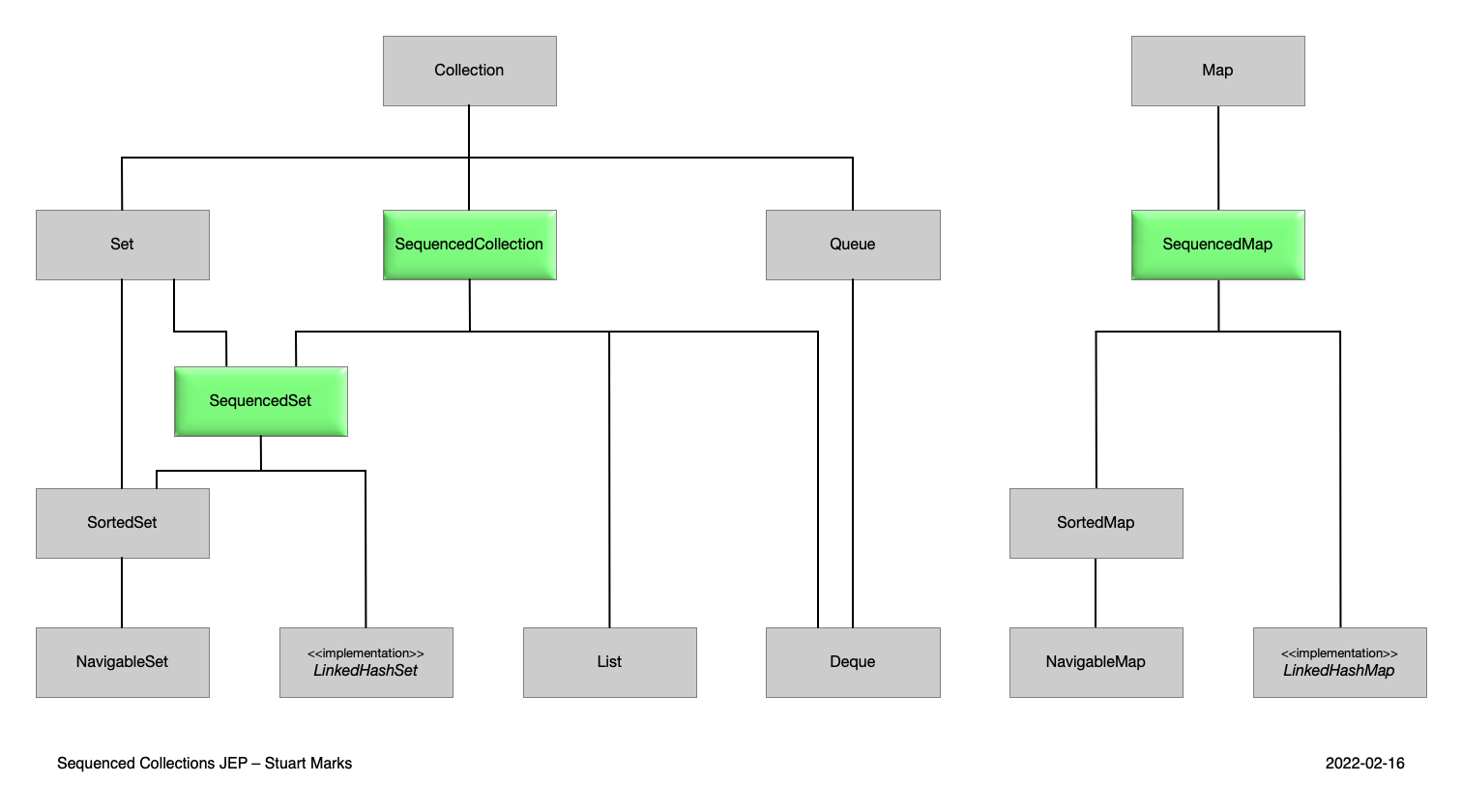
interface SequencedCollection<E> extends Collection<E> {
// new method
SequencedCollection<E> reversed();
// methods promoted from Deque
void addFirst(E);
void addLast(E);
E getFirst();
E getLast();
E removeFirst();
E removeLast();
}
452: Key Encapsulation Mechanism API
기존 대칭키 암호화 방식의 문제점
전통적인 대칭키 암호화에서는 키를 무작위로 생성하고, 이 키를 안전하게 공유하기 위해 수신자의 공개 키로 암호화합니다. 그러나 이 방법은 데이터를 공개 키 암호화 알고리즘에 맞게 조정하기 위해 추가적인 ‘패딩’이 필요하며, 이 과정이 보안성을 증명하기 어렵고 보안에 취약할 수 있다.
KEM 도입
이런 문제를 해결하기 위해 자바에 도입된 새로운 암호화 방식이다. KEM은 대칭키를 직접 암호화하는 대신, 공개 키를 활용하여 관련 대칭 키를 유도하는 방식을 사용한다. 이 과정에서는 복잡한 패딩 절차가 필요 없으며, 결과적으로 보안이 강화된다.
대칭 키를 직접 공개 키로 암호화하는 대신, 공개 키를 이용하여 ‘대칭 키를 얻을 수 있는 방법’을 생성하고 수신자에게 보내 수신자는 이 방법을 통해 실제 대칭 키를 얻는다. 이 과정에서는 패딩이 필요하지 않으며, 이로 인해 더 단순하고 보안적으로 더 강력하다.
현재 사용되는 많은 공개 키 암호화 방식은 여러 수학적 문제에 기반을 둔다. 예를 들어 RSA 암호화 방식은 큰 소수를 찾는 문제에 기반한다.
현재 양자 컴퓨터의 개발이 이루어지고 있고 이는 현재 사용되고 있는 공개키의 크나큰 보안 위험 요소이다. KEM은 양자 공격을 방어하는 데 중요한 도구가 될 것이고 여러 보안 업체들이 이미 표준 KEM 표준화하는 API에 대한 필요성을 표명했다.
public final class KEM {
...
public static final class Encapsulator {
String providerName();
int secretSize(); // Size of the shared secret
int encapsulationSize(); // Size of the key encapsulation message
Encapsulated encapsulate();
Encapsulated encapsulate(int from, int to, String algorithm);
}
public static final class Decapsulator {
String providerName();
int secretSize(); // Size of the shared secret
int encapsulationSize(); // Size of the key encapsulation message
SecretKey decapsulate(byte[] encapsulation) throws DecapsulateException;
SecretKey decapsulate(byte[] encapsulation, int from, int to,
String algorithm)
throws DecapsulateException;
}
}
442: Foreign Function & Memory API (Third Preview)
446: Scoped Values (Preview)
448: Vector API (Sixth Incubator)
언어 개선 및 패턴 매칭
430: String Templates (Preview)
기존에 문자열을 만들 때 읽기 어려운 코드, 장확하고, 매개 변수에서 분리하여 소수성과 유형 불일치와 같은 여러 문제들이 존재한다.
String s = x + " plus " + y + " equals " + (x + y);
String s = new StringBuilder()
.append(x)
.append(" plus ")
.append(y)
.append(" equals ")
.append(x + y)
.toString();
String s = String.format("%2$d plus %1$d equals %3$d", x, y, x + y);
String t = "%2$d plus %1$d equals %3$d".formatted(x, y, x + y);
자바에서 새로운 템플릿 표현식이 추가되었고 개발자들이 안전하고 효율적으로 문자열을 구성할 수 있도록 지원한다.
사용법 : STR."\{field name|method|arithmetic}"
// Embedded expressions can be strings
String name = "Joan";
String info = STR."My name is \{name}";
assert info.equals("My name is Joan"); // true
// Embedded expressions can perform arithmetic
int x = 10, y = 20;
String s = STR."\{x} + \{y} = \{x + y}";
// Embedded expressions can invoke methods and access fields
String s = STR."You have a \{getOfferType()} waiting for you!";
String t = STR."Access at \{req.date} \{req.time} from \{req.ipAddress}";
String json = STR."""
{
"name": "\{name}",
"phone": "\{phone}",
"address": "\{address}"
}
""";
440: Record Patterns
레코드 패턴을 통해 레코드 값을 분해하여 보다 정교한 데이터 작업을 가능하게 한다.
record Point(int x, int y) {}
자바 16부터 도입된 레코드는 데이터를 운반하는 데 최적화된, 불변의 객체를 정의하기 위한 짧고 간결한 방법을 제공
Java 16에서 확장된 instanceof 연산자의 타입 패턴으로 타입 캐스팅을 단순화하였다.
// Prior to Java 16
if (obj instanceof String) {
String s = (String)obj;
... use s ...
}
// As of Java 16
if (obj instanceof String s) { // s 패턴 변수
... use s ...
}
기존에 레코드 타입의 클래스를 instanceof 연산자로 사용하려면 다음과 같이 사용하였다.
// As of Java 16
record Point(int x, int y) {}
static void printSum(Object obj) {
if (obj instanceof Point p) {
int x = p.x();
int y = p.y();
System.out.println(x+y);
}
}
이번에 도입되는 레코드 패턴은 레코드의 구성 요소를 패턴 변수로 할당이 가능해졌다. 이렇게 되어 추가적인 접근자 메서드 호출 없이 x, y 를 바로 사용할 수 있게 되어 코드가 더욱 간결해졌다.
// As of Java 21
static void printSum(Object obj) {
if (obj instanceof Point(int x, int y)) { // x, y 패턴 변수
System.out.println(x+y);
}
}
441: Pattern Matching for switch
Pattern Matching을 switch 문에서도 사용할 수 있도록 지원한다.
Pattern Matching
특정한 형식이나 구조를 가진 데이터를 인식하고, 그에 맞게 동작을 결정하는 방법
기존에는 switch 문에 제한된 타입의 값으로 열거형, 정수, 문자열만 가능했지만 이제는 객체 타입에 따라 분기를 가능하게 한다.
// Prior to Java 21
static String formatter(Object obj) {
String formatted = "unknown";
if (obj instanceof Integer i) {
formatted = String.format("int %d", i);
} else if (obj instanceof Long l) {
formatted = String.format("long %d", l);
} else if (obj instanceof Double d) {
formatted = String.format("double %f", d);
} else if (obj instanceof String s) {
formatted = String.format("String %s", s);
}
return formatted;
}
// As of Java 21
static String formatterPatternSwitch(Object obj) {
return switch (obj) {
case Integer i -> String.format("int %d", i);
case Long l -> String.format("long %d", l);
case Double d -> String.format("double %f", d);
case String s -> String.format("String %s", s);
default -> obj.toString();
};
}
널 타입에 대한 처리가 가능해져 따로 널 처리를 위한 코드를 따로 작성하지 않아도 된다.
// Prior to Java 21
static void testFooBarOld(String s) {
if (s == null) {
System.out.println("Oops!");
return;
}
switch (s) {
case "Foo", "Bar" -> System.out.println("Great");
default -> System.out.println("Ok");
}
}
// As of Java 21
static void testFooBarNew(String s) {
switch (s) {
case null -> System.out.println("Oops");
case "Foo", "Bar" -> System.out.println("Great");
default -> System.out.println("Ok");
}
}
when이 추가되어 조건 식도 추가할 수 있다. 좀 더 세분화된 처리가 가능해졌다.
// As of Java 21
static void testStringNew(String response) {
switch (response) {
case null -> { }
case String s
when s.equalsIgnoreCase("YES") -> {
System.out.println("You got it");
}
case String s
when s.equalsIgnoreCase("NO") -> {
System.out.println("Shame");
}
case String s -> {
System.out.println("Sorry?");
}
}
}
443: Unamed Patterns and Variables (Preview)
레코드 패턴의 가독성을 개선하고 선언은 필요하지만 사용 되지 않은 변수를 식별하여 코드의 유지보수성을 향상시킨다.
불필요한 패턴이나 변수를 사용하지 않도록 하여, 코드를 간결하게 명확하게 만든다.
if (r instanceof ColoredPoint(Point(int x, int y), _)) { ... }
for (Order _: orders) {
}
try {
}
catch (NumberFormatException _) {
}
동시성 및 멀티스레딩
439: Generational ZGC
GC 순서
Serial GC → Parallel GC → Concurrent Mark-Sweep(CMS) GC → G1 GC → ZGC
weak generational hypothesis 이라는 가설은 대부분의 객체는 젊고 늙기 전에 GC에 의해 수거된다. 즉, 비교적 짧은 시간만 생존한다는 말이다.
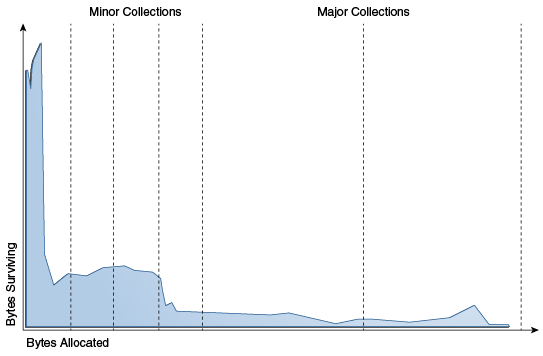
이전 세대 GC에서는 Young Generation, Old Generation 영역을 나누어 효율적으로 관리하였지만 ZGC는
ZGC currently stores all objects together, regardless of age, so it must collect all objects every time it runs.
모든 객체를 Generation 영역 구분 없이 함께 저장하여 실행될 때 모두 동시에 수집되어야 한다. 가설의 이점을 활용 하지 않아 비효율적이다.
ZGC 또한 Generation 영역을 분리함으로써 young, old objects를 구분하여 관리하여 좀 더 효율적으로 수집할 수 있는 구조로 변경하였다.
444: Virtual Threads
가상 스레드의 도입 배경
고전적인 멀티스레딩 모델에서는 I/O 작업 중 많은 스레드가 Blocking 되면서 리소스가 낭비되었다. 이는 많은 메모리 사용과 CPU 시간의 비효율적 사용으로 이어졌다.
이러한 문제를 해결하기 위해 비동기 I/O로 Webflux와 같은 프레임워크를 사용해왔지만, 러닝 커브 존재와 동시에 비동기로 인해 단일 스레드로 처리하는 것이 아니어서 신경 써야 할 부분들이 존재했다.
가상 스레드 도입
가상 스레드는 위에서 언급한 문제를 해결하고 I/O 중심의 작업에 처리량을 증가시키기 위해 도입
가상 스레드 구조
기존 Java의 스레드 모델은 Java의 유저 스레드를 만들면 Java Native Interface(JNI)를 통해 커널 영역을 호출하여 OS가 커널 스레드를 생성하고 매핑하여 작업을 수행한다.
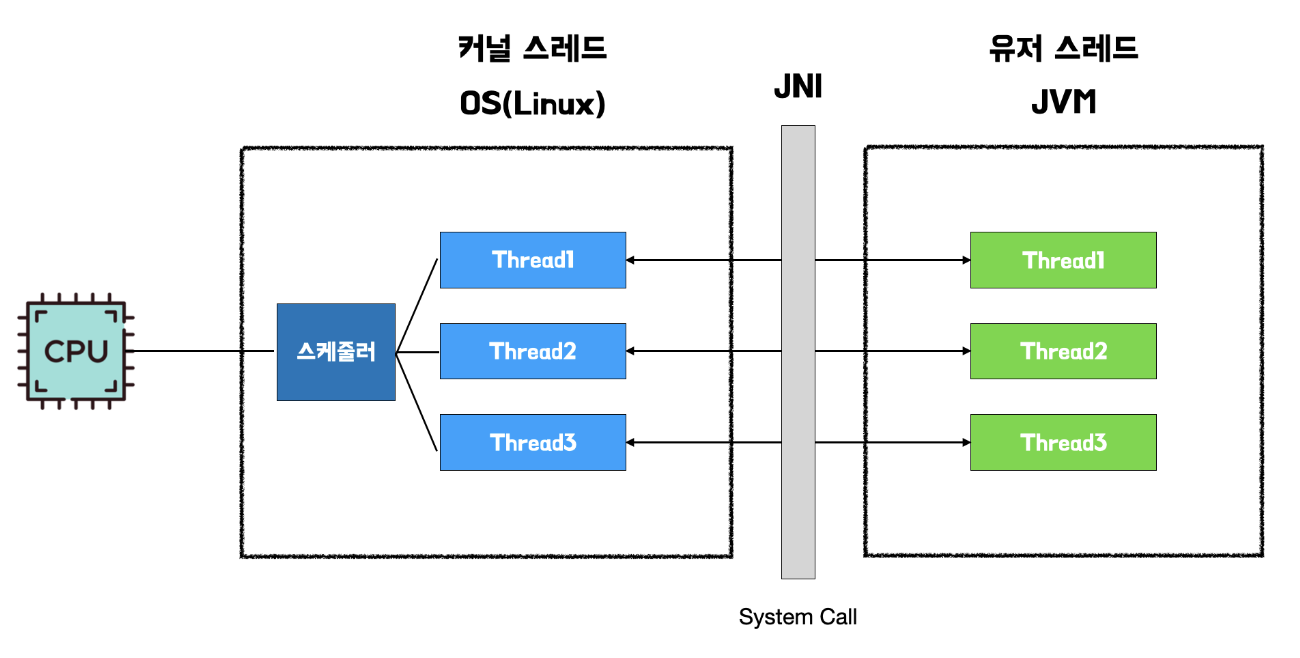
Virtual Thread는 기존 Java의 스레드 모델과 달리, 플랫폼 스레드와 가상 스레드로 나뉜다. 플랫폼 스레드 위에서 여러 Virtual Thread가 번갈아 가며 실행되는 형태로 동작한다.
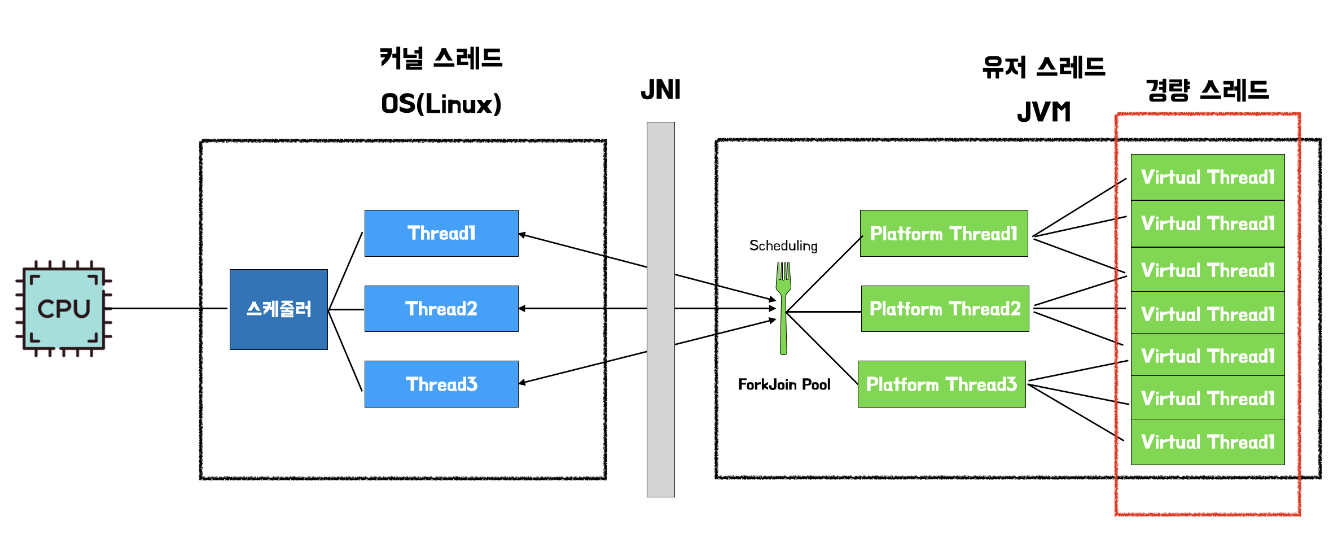
가상 스레드의 성능 이점
- 컨텍스트 스위칭 비용 감소 : 플랫폼 스레드를 더 쪼갠 경량형 스레드이기 때문에 옮길 데이터가 적기 때문에 비용 감소
- 메모리 사용 감소 : 플랫폼 스레드에서 가상 스레드를 쪼개면 되니 플랫폼 스레드를 많이 유지할 필요 없어 메모리 사용이 감소
- I/O 블로킹에 따른 리소스 낭비 감소 : 블로킹 되면 기다리는 것이 아니라 다른 가상 스레드로 옮겨가기 때문에 리소스 낭비가 감소
가상 스레드 사용 시 유의사항
- synchronized 블록 사용 시 Blocking
- ThreadLocal 을 지원하지만, 기존 플랫폼 스레드와 다르게 가상 스레드의 수는 상당히 많은 수가 생성될 수 있으므로 주의해야한다.
- 가상 스레드의 비용은 저렴하기 때문에 가상 스레드는 따로 풀링할 필요가 없다.
- CPU Bound 작업이 주라면 성능상 이점을 볼 수 없다.
- 가상 스레드 스위칭이 발생하지 않는데 플랫폼 스레드 사용과 추가로 가상 스레드의 생성과 스케줄링 비용만 더 들어가기 때문이다.
453: Structured Concurrency (Preview)
플랫폼 개선
449: Deprecate the Windows 32-bit x86 Port for Removal
32비트 운영을 지원하는 Window 10이 2025년 10월에 종료할 예정이고 가상 스레드의 지원 하기에는 어려원 환경 등 여러 복합적인 이유로 인해서 더 현대적이고 성능이 우수한 64비트에 집중하고 32비트 점진적으로 폐지하는 것으로 결정하였다.
이번에는 32비트에서 빌드시에 오류 메시지를 발생시키는 빌드 시스템의 업데이트가 포함되었다.
451: Prepare to Disallow the Dynamic Loading of Agents
자바 에이전트를 통해서 동적으로 애플리케이션 코드를 수정하는 것을 허용해왔고 이를 통해 모니터링을 관찰하는 방법이 많이 탄생하게 되었다.
문제점
- 동적을 로드된 에이전트는 애플리케이션 동작에 영향을 미칠 수 있다. 예를 들어 악의적인 에이전트는 애플리케이션의 동작 변경하여 보안을 침해할 수 있다.
- 에이전트가 동적으로 로드되면서 애플리케이션의 무결성을 손상할 수 있다. 애플리케이션 소유자 승인 없이 애이전트를 로드하는 것은 애플리케이션의 예상치 않은 동작을 초래할 수 있어 무결성을 저해할 수 있다.
다음과 같은 문제로 보안과 무결성을 해친다.
실행중인 JVM에 동적으로 agent가 적재되는 것을 경고하도록 수정이 되었고 이러한 경고는 향 후 릴리스에 에이전트를 지원하지 않는 것에 대해서 준비시키기는 것을 목표로 한다.