
위 그림과 같이 게시글(Board)과 댓글(Comment)의 단방향 연관관계에서 해당 테이블을 조회할 때 발생하는 N+1 문제에 대해서 알아보겠습니다.
예제 소스 파일 : Github
N+1 문제란?
N+1이란 엔티티 하나을 조회하기 위해서 연관된 엔티티까지 조회 쿼리문이 N+1번 날라간다는 말이다
이로 인해 시스템에 심각한 성능 저하가 일어날 수 있다
위 그림을 예로 설명하면 Comment를 조회하려고 할 때 전체 Comment를 한번 조회하고 각 Comment가 가지고 있는 Board에 대해서 조회를 한번 씩 더 하게 된다
- Comment 조회 - 1번
- Comment의 갯수(각 Comment가 가지고 있는 Board 조회) - N번
이렇게 하면 N+1번의 쿼리가 발생하는 것이다
보통 데이터베이스에서 단일 테이블을 조회하려고 할때 쿼리문일 하나만 날라갈 것이다
select * from Comment
외래키를 포함한 테이블은 상대 테이블의 데이터를 가져 오기 위해서는 조인을 이용해서 테이블을 조회할 될 것이다
select * from Comment c inner join Board b on c.board_id = b.board_id
이렇듯 하나의 쿼리문으로 해결되어야 되야하지만 N번 더 발생하게 되는 것이다
소스코드로 어떻게 발생하는 것인지 알아보자
@Entity
@Getter @Setter
public class Board {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "board_id")
Long id;
String title;
String content;
}
public interface BoardRepository extends JpaRepository<Board, Long> {
}
@Entity
@Getter @Setter
public class Comment {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "comment_id")
Long id;
String content;
@ManyToOne
@JoinColumn(name = "board_id")
Board board;
}
public interface CommentRepository extends JpaRepository<Comment, Long> {
}
예제에 있는 두 테이블을 Entity와 Repository를 위와 같이 작성했다
@Test
public void 연관관계_findAll() throws Exception {
//given
for (int i = 0; i < 3; i++) {
Board board = new Board();
board.setContent("게시글 내용");
boardRepository.save(board);
Comment comment = new Comment();
comment.setContent("덧글 내용");
comment.setBoard(board);
commentRepository.save(comment);
}
//when
List<Comment> comments = commentRepository.findAll();
}
- board1 - comment1
- board2 - comment2
- board3 - comment3
테스트를 통해 데이터베이스에 위와 같이 데이터를 넣고 모든 comment를 출력하도록 하였다
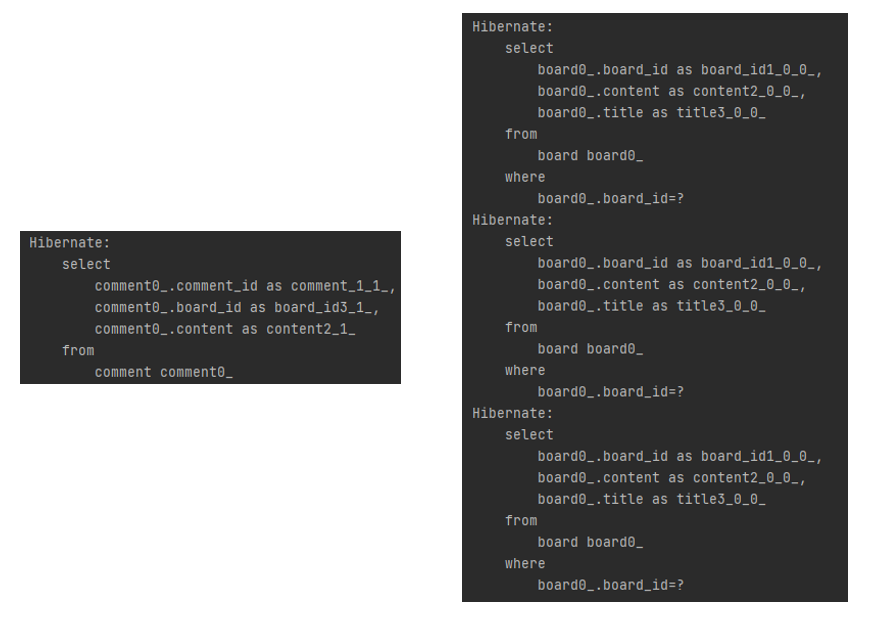
사진에서 알 수 있듯이 모든 comment를 조회하는 쿼리문 1개와 각 comment에서 외래키로 가지고 있는 board를 조회하는 쿼리문이 N개가 발생하였다
만약 Board가 50만개이고 각각에 comment가 하나씩 달려있다고 가정할 때 모든 comment 검색하려고 할때마다 5000001개의 쿼리가 발생하는 상상만해도 끔찍한 결과가 초래할 것이다
이를 해결 하기 위한 방법에 대해서 알아보도록 하자
N+1 해결방법
내가 아는 해결할 수 있는 방법에는 총 세가지가 있다.
- GlobalFetch
- Fetch Join
- EntityGraph
아래에서 세가지 방법이 어떤 것인지 어떻게 사용하는 것인지에 대해서 살펴보도록 하자
Global Fetch Strategy
글로벌 패치 전략이란, 엔티티를 생성할 때(컴파일 시점) 결정 되는 연관관계 전략이다
public class Comment {
...
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "board_id")
Board board;
}
해결방법은 @ManyToOne 속성에 fetch 속성으로 LAZY를 주면 된다
이때 줄 수 있는 값으로 LAZY와 EAGER 두가지 있다
LAZY: comment를 조회할 때 comment만 조회하고 연관된 엔티티는 필요로 하는 시점이 되면 발생하게 조회가 발생하게 된다
@Test
public void 연관관계_findAll() throws Exception {
//when
List<Comment> comments = commentRepository.findAll();
}
위와 같이 모든 comment를 조회하려고 할 떄 이전과 같이 board도 같이 가져오는 것이 아닌 comment만 가져오게 된다
@Test
@Transactional
public void 연관관계_findAll() throws Exception {
//when
List<Comment> comments = commentRepository.findAll();
//then
for(Comment c: comments){
c.getBoard().getContent();
}
}
@Transactional 어노테이션을 달아 꼭 트랜잭션 범위를 정해주어야 한다. 그렇지 않으면 findAll 하나가 트랜잭션 범위 내이기 때문에 comments는 비영속성 상태가 되어 Board를 불러오려고 하면 lazyinitializationException 예외 오류가 발생할 것이다
comments에 board 내에 값을 필요로 하여 불러오게 되면 그때 각 board에 대한 조회 쿼리문이 발생하게 된다
EAGER: Comment를 조회할 때 연관된 엔티티를 포함하여 한번에 발생되도록 한다@ManyToOne은 Default가EAGER이므로 N+1의 문제가 발생한 것이다
Fetch Join
조인할 때 연관된 엔티티나 컬렉션를 함께 조회하려고 할 때 사용한다 결과는 EAGER와 똑같지만 과정은 다르다 EAGER의 경우에는 N+1 쿼리가 발생하지만 Fetch Join의 경우에는 한번이 쿼리문으로 해결이 가능하다
public interface CommentRepository extends JpaRepository<Comment, Long> {
@Query("select c from Comment c join fetch c.board")
List<Comment> findAll();
}
Spring Data JPA 에서는 @Query 어노테이션을 이용하여 JPQL를 생성할 수 있다
사용하는 방법은 위와 동일하게 join fetch 뒤에 연관된 엔티티나 컬렉션을 적어주면 된다
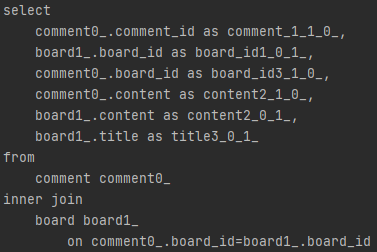
날라간 쿼리문은 위 사진과 같이 comment와 board가 함께 조회되는 것을 볼 수 있다
EntityGraph
@EntityGraph도 마찬가지로 EntityGraph 상에 있는 Entity들의 연관관계 속에서 필요한 엔티티와 컬렉션을 함께 조회하려고 할때 사용한다
public interface CommentRepository extends JpaRepository<Comment, Long> {
@EntityGraph(attributePaths = {"board"}, type = EntityGraph.EntityGraphType.LOAD)
List<Comment> findAll();
}
Spring Data JPA에서 적용하려는 메소드 위에 @EntityGraph 어노테이션을 달고 옵션을 준다
attributePaths는 같이 조회할 연관 엔티티명을 적으면 된다 ,(콤마)를 통하여 여러개를 줄 수도 있다
type은 EntityGraphType.LOAD, EntityGraphType.FETCH 2가지가 있다
LOAD: attributePaths에 정의한 엔티티들은 EAGER, 나머지는 글로벌 패치 전략에 따라 패치한다FETCH: attributePaths에 정의한 엔티티들은 EAGER, 나머지는 LAZY로 패치한다
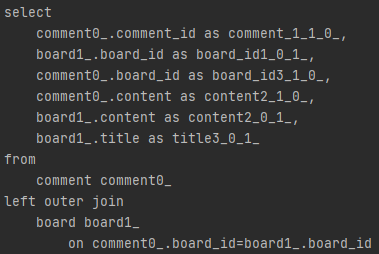
위와 같이 comment와 board가 함께 조회된 것을 볼 수 있다
EntityGraph 주의사항
Fetch join과 결과가 비슷한 것처럼 보이지만 차이점이 존재한다
Fetch join의 경우 따로 left outer join은 명시하여 주지 않는 이상 inner join을 하는 반면에 EntityGraph의 경우에는 기본적으로 left outer join을 하고 있다
이때 조심해야 될 점은 left outer join이기 때문에 필요 이상의 컬럼이 조회될 수 있다 최악의 경우에 카디션곱의 결과를 가져올 수도 있다
특히 OneToMany의 경우 board가 가지는 comment의 수만큼 컬럼이 중복으로 발생하기 때문에 이부분은 따로 조회하는 것이 올바른 방법이다
컬렉션 타입을 Set으로 변경하여 중복을 제거 하는 방법도 있지만 중복 제거 비용을 감안하면 따로 조회를 하는 방법이 더 나을 것이다
끝까지 읽어주셔서 감사합니다