영속성 컨텍스트란?
직접 삭제 또는 초기화를 진행하지 않는이상 영구적으로 엔티티 데이터들을 저장하고 관리하는 공간이라고 생각하면 된다
@Repository
@RequiredArgsConstructor
public class CommentRepository {
private final EntityManager em;
public Comment save(Comment comment){
em.persist(comment); // <-
return comment;
}
public Comment findOne(Long id){
return em.find(Comment.class, id); // <-
}
public Comment remove(Comment comment){
em.remove(comment); // <-
return comment;
}
}
예제 소스와 같이 저장, 조회, 수정을 구현하여 각 함수들을 호출하게 되면 해당하는 엔티티의 상태 정보들을 영속성 컨텍스트에서 관리하게 된다
엔티티의 생명주기
엔티티 생명주기에는 총 4가지의 상태가 존재한다
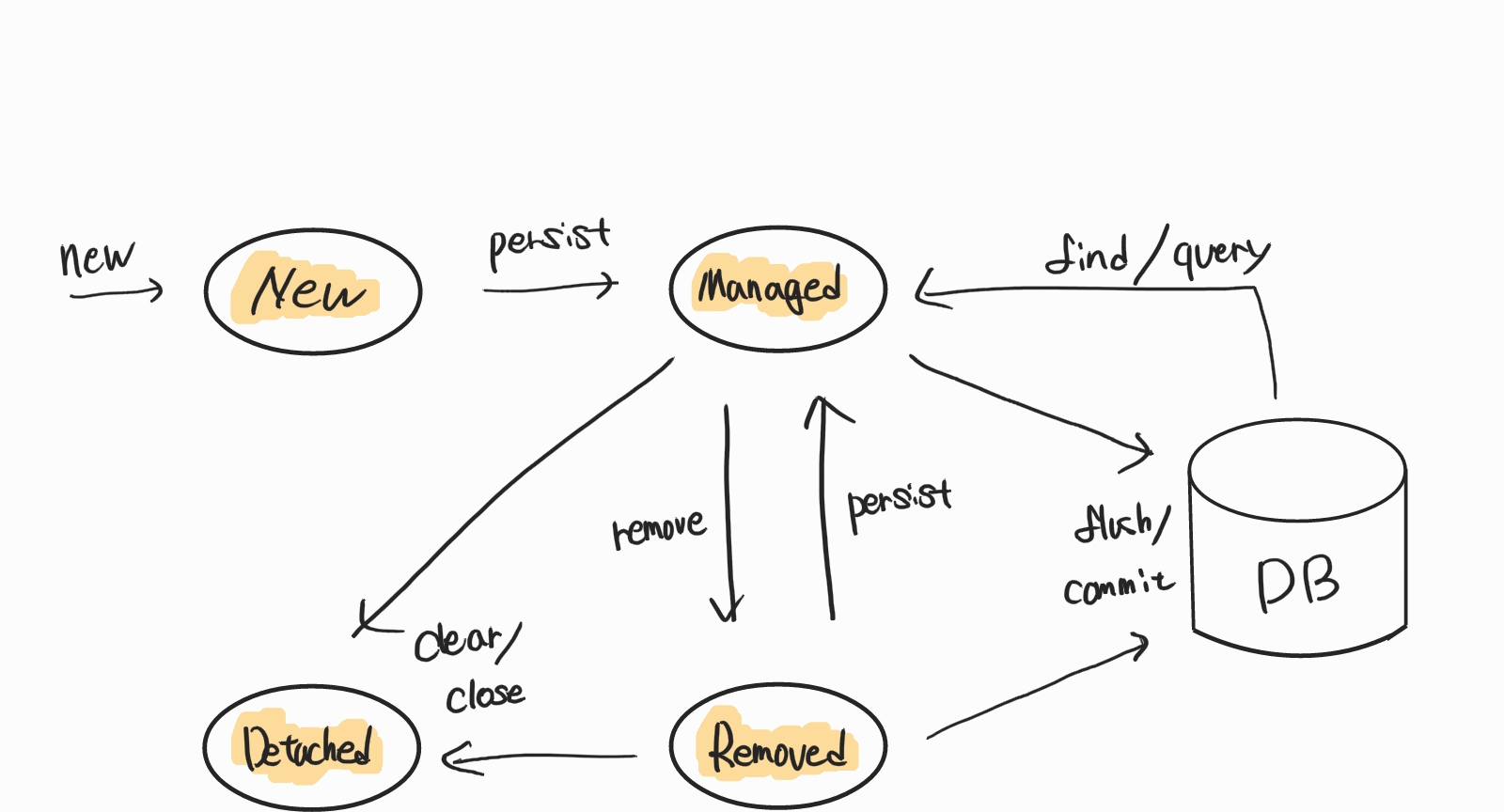
- 비영속(new/transient) : 영속성 컨텍스트와 관계가 없는 엔티티
Comment comment = new Comment(); - 영속(persistent/managed) : 영속성 컨텍스트에서 관리하는 엔티티
em.persist(comment); - 준영속(detached) : 영속성 컨텍스트에서 관리하고 있다가 분리된 엔티티
em.detach(comment); em.clear(); // 영속성 컨텍스트 초기화 em.close(); // 영속성 컨텍스트 종료 - 삭제(removed) : 영속성 컨텍스트와 데이터베이스에서 제거된 엔티티
em.remove(comment);
영속성 컨텍스트 특징
식별자로 구분
영속성 컨텍스트는 엔티티를 식별자의 값으로 구분하기 때문에 식별자 값이 반드시 존재해야 한다
데이터베이스에 저장
영속성 컨텍스트에 엔티티를 저장하는 순간 데이터베이스에 바로 적용되는 것이 아니고 flush를 사용하는 시점에 영속성 컨텍스트의 변경 내용들에 대해서 데이터베이스에 적용하게 된다
플러시(flush) 사용 시점
- em.flush()를 직접 호출 시
Comment comment = new Comment(); em.persist(comment); em.flush(); // <- - 트랜잭션 커밋 시 플러시가 자동 호출 트랜잭션 커밋 시 자동으로 flush가 발생하게 된다
em.begin(); em.persist(comment); em.persist(comment2); em.commit(); // <- flush() 발생 - JPQL 쿼리 실행 시 플러시가 자동 호출 JPQL은 내부적으로 SQL로 변경되어 데이터베이스에서 동작하게 되는데 flush가 사전에 되어있지 않으면 값을 올바르게 가져올 수 없기 때문에 이런 문제를 해결하기 위해 JPQL 동작 전에 사전에 flush()를 하게 된다
em.persist(comment); em.persist(comment); em.createQuery("select c from Comment c", Comment.class); // <- flush() 발생
영속성 컨텍스트 사용 이점
1차 캐시
영속성 컨텍스트 내부에는 1차 캐시라는 공간이 존재하고 그 곳에 영속 상태의 엔티티들이 모두 저장된다
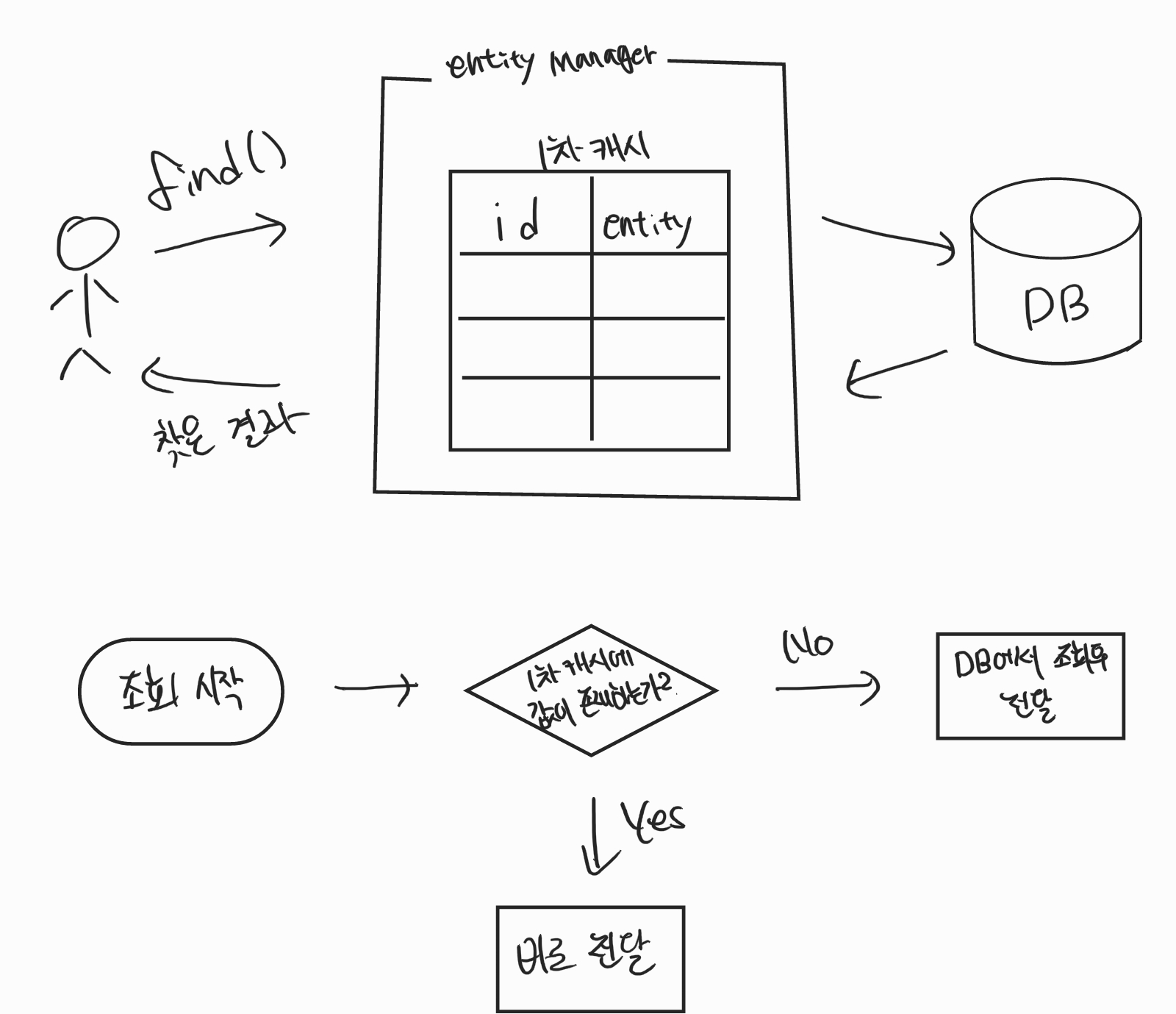
1차 캐시는 ID로 식별하기 때문에 ID - Entity와 같이 Map 구조로 존재한다
조회하려고 할 때
- 1차 캐시에 값이 존재 O : 1차 캐시 값을 그대로 전달
- 1차 캐시에 값이 존재 X : DB에서 쿼리문을 날려 조회 한 후 1차 캐시에 저장하고 전달
1차 캐시에 값이 존재하게 되면 DB를 거치지 않아도 되기 때문에 성능상에 이점을 얻을 수 있다
하지만 JPQL을 이용할 경우에는 값이 존재하더라도 무조건 쿼리문을 날리게 된다
동일성 보장
같은 값을 두번 꺼내려고 할때 각각 꺼내진 두 엔티티는 같은 주소를 가르키고 있다
Comment c = em.find(Comment.class, 1);
Comment c2 = em.find(comment.class, 1);
c == c2 // true
트랙잭션을 지원하는 쓰기 지연
영속 컨텍스트에는 1차 캐시와 함께 쓰기 지연 SQL 저장소가 존재한다
이곳에는 commit(flush)를 하기 전에 수행 했던 내용들의 쿼리문들을 저장하고 있다가 commit을 하는 순간 모든 SQL문을 DB에 반영하게 된다
쓰기 지연을 이용하면 한 번 동작할 때마다 DB를 거치는 것이 아니라 필요로 할 때 한번씩 DB를 거치기 때문에 성능에 유리할 수 있다
변경 감지
JPA는 값을 변경해주는 메소드를 제공하지 않는다 영속 상태에 있는 엔티티는 알아서 변경되었음을 감지한다
엔티티를 저장할 때 최초의 상태를 저장하는데 이것을 스냅샷이라고 하고 flush하게 되면 entity와 스냅샷을 비교하여 변경된 내용에 대해서 자동으로 update 쿼리를 만들어 전달하게 된다
- flush()를 하면 스냅샷과 엔티티 비교
- 변경된 내용에 대해서 Update SQL 생성
- 데이터베이스에 반영(commit)
지연 로딩
지연 로딩은 연관된 엔티티(참조 객체) 데이터를 가져오지 않고 필요한 시점에 엔티티(참조 객체) 값을 가져오려고 할 때 쿼리문을 발생시키는 것을 말한다
이렇게 하면 불필요한 데이터 참조를 줄일 수 있다
지연 로딩으로 설정하기 위해서는 패치 전략을 LAZY로 설정하면 된다
패치 전략 종류
- LAZY : 지연 로딩, 실제 엔티티 대신 프록시 객체(위장 엔티티)로 대신한다
- EAGER : 처음부터 연관된 엔티티(참조 객체)를 모두 가져온다, N+1 발생이 무분별하게 생길 수 있기 때문에 LAZY를 기본값으로 사용하는 것이 좋다
N+1 관련 내용 : 링크
긴 글 읽어주셔서 감사합니다