
워밍업
extends / implements 사용하지 않기
- Querydsl을 사용하기 위해 아래 그림처럼 사용하거나
QuerydslRepositorySupport를 상속받아 사용했다.
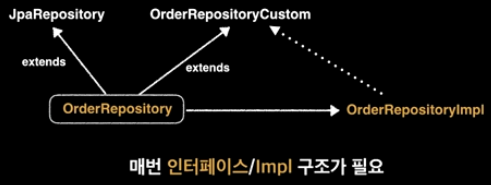
- 꼭 무언가를 상속/구현을 받지 않더라도, 꼭 특정 Entity를 지정하지 않더라도 Querydsl을 사용할 수 있는 방법?
JPAQueryFactory만 있다면 Querydsl을 사용하는 데에 문제가 없다.
@RequiredArgsConstructor
@Repository
public class UserRepository {
private final JPAQueryFactory queryFactory;
}
동적쿼리는 BooleanExpression
- 일반적으로 동적쿼리를 사용할 때
BooleanBuilder사용해서 동적쿼리를 만들게 되는데 쿼리를 예상하기 어렵다. BooleanExpression을 이용하면 함수로 만들어 null 반환 시 자동으로 조건절에서 제거되며 좀 더 알아보기 쉽다.
// BooleanBuilder
public List<Academy> findDynamicQuery(...) {
BooleanBuilder bulider = new BooleanBuilder();
if (!StringUtils.isEmpty(name)) {
builder.and(academy.name.eq(name));
}
if (!StringUtils.isEmpty(address)) {
builder.and(academy.address.eq(address));
}
if (!StringUtils.isEmpty(phoneNumber)) {
builder.and(academy.phoneNumber.eq(phoneNumber));
}
queryFacotry.selectFrom(academy)
.where(builder)
.fetch();
}
// BooleanExpression
public List<Academy> findDynamicQuery(...) {
queryFacotry.selectFrom(academy)
.where(
eqName(name),
eqAddress(address),
eqPhoneNumber(phoneNumber))
.fetch();
private BooleanExpression eqName(String name) {
if (StringUtils.isEmpty(name)) return null;
return academy.name.eq(name);
}
private BooleanExpression eqAddress(String address) {
if (StringUtils.isEmpty(address)) return null;
return academy.address.eq(address);
}
private BooleanExpression eqPhoneNumber(String phoneNumber) {
if (StringUtils.isEmpty(phoneNumber)) return null;
return academy.phoneNumber.eq(phoneNumber);
}
}
성능개선 - Select
exists 메소드 금지
- exists를 사용하는 것이 count보다 성능이 더 잘 나오게 된다.
- exists는 특정 조건에 맞는 행을 찾았을 때 바로 종료되는 반면 count 쿼리는 모든 데이터를 조회 후 판단하기 때문이다.
- exists로 조건에 맞는 행을 빨리 찾을수록 count 쿼리와의 속도 차이는 극심해진다.
// exists
select exists(
select 1
from ad_item_sum
where created_date > '2020-01-01'
)
// count
select count(1) from ad_item_sum where created_date > '2020-01-01'
- Querydsl exists는 sql exist가 아닌 count 쿼리를 사용하기 때문에 성능 이슈가 발생한다.
- 그래서 아래와 같이 limit 1로 한 쿼리를 찾으면 종료할 수 있도록 구현한다.
- 주의해야 할 점은 해당 값을 찾지 못하면 0이 아니라 null이 반환되기에 null 체크가 필요하다.
public Boolean exist(Long bookId) {
Integer fetchOne = queryFactory
.selectOne()
.from(book)
.where(book.id.eq(bookId))
.fetchFirst();
return fetchOne != null;
}
// fetchFirst == limit(1).fetchOne()
cross join 회피
- cross join은 성능이 좋지 않기 때문에 지양하는 것이 좋다.
- 실제로 조인을 하지 않아도 조건절에 조인에 대해서 직접 사용하게 되면 묵시적 join으로 cross join이 발생한다.
// Querydsl
public List<Customer> crossJoin() {
return queryFactory
.selectFrom(customer)
.where(customer.customerNo.gt(customer.shop.shopNo))
.fetch();
}
// JPQL
@Query("SELECT c FROM Customer c WHERE c.customerNo > c.shop.shopNo")
List<Customer> crossJoin();
- 명시적 join을 하게 되면 Inner join이 발생하게 된다.
public List<Customer> crossJoin() {
return queryFactory
.selectFrom(customer)
.innerJoin(customer.shop, shop)
.where(customer.customerNo.gt(shop.shopNo))
.fetch();
}
Entity 보다는 Dto 를 우선
- Entity를 조회하게 되면 불필요한 컬럼 조회, OneToOne N+1 쿼리가 발생한다.
- 단순히 조회인데도 성능 이슈가 될만한 문제들이 발생한다.
- 어떤 상황에 써야 하나?
- Entity : 실시간으로 Entity 변경이 필요한 경우
- Dto : 고강도 성능 개선 or 대량의 데이터 조회가 필요한 경우
// Entity
queryFactory
.selectFrom(book)
.where(book.bookNo.eq(bookNo))
.offset(pageNo)
.limit(10)
.fetch();
// Dto
queryFactory
.select(Projections.fields(BookPageDto.class,
book.name,
book.bookNo,
book.id
))
.from(book)
...
조회컬럼 최소화하기
- 이미 알고 있는 값은 조회할 필요가 없기에 as 표현 식으로 대체한다.
- as 컬럼은 조회 컬럼에서 제외되기 때문에 성능 향상
// before
public List<BookPageDto> getBooks(int bookNo, int pageNo) {
queryFactory
.select(Projections.fields(BookPageDto.class,
book.name,
book.bookNo,
book.id
))
.from(book)
...
}
// after
public List<BookPageDto> getBooks(int bookNo, int pageNo) {
queryFactory
.select(Projections.fields(BookPageDto.class,
book.name,
Expressions.asNumber(bookNo).as("bookNo"),
book.id
))
.from(book)
...
}
Select 컬럼에 Entity 자제 - 불필요한 컬럼 조회
- 관계에 있는 엔티티의 id만 필요한 상황이라고 가정
- id를 얻기 위해 조회 컬럼에 entity를 조회하게 되면 id뿐만 아니라 불필요한 모든 데이터까지 전부 조회하게 된다.
queryFactory
.select(Projections.fields(AdBond.class,
...
adItem.customer
)
)
Select 컬럼에 Entity 자제 - N + 1
- shop과 customer가 OneToOne 관계이기에 Shop이 매 건 조회된다.
- 이유는 OneToOne는 기본적으로 EAGER 전략을 따르기 때문이다.
Select 컬럼에 Entity 자제 - distinct
- select에 선언된 entity의 컬럼 전체가 distinct 대상이 되기 때문에 customer 모든 컬럼 또한 대상이 되어 성능 이슈가 발생한다.
Entity간 연관관계를 맺으려면 반대 Entity가 필요하지 않나?
- Select 컬럼에 엔티티를 썼을 때 위에서 알아봤듯이 문제가 될 이슈들이 정말 많다.
- 연관된 Entity의 save를 위해서는 반대편 Entity의 id만 있으면 된다.
queryFactory
.select(Projections.fields(AdBond.class,
adItem.txDate,
...
adItem.customer.id.as("customerId")
)
)
public AdBond toEntity() {
return AbBond.builder()
.txDate(txDate)
...
.customer(new Customer(cusomerId))
.build();
}
Group By 최적화
- Mysql에서 group by를 실행하면 인덱스를 타지 않았을 때 Filesort가 필수적으로 실행된다.
explain select 1
from ad_offset
group by customer_no;
order by null을 하게 되면 Filesort가 제거된다.
explain select 1
from ad_offset
group by customer_no
order by null asc;
- 하지만 Querydsl은 order by null을 지원하지 않기 때문에 직접 클래스를 생성
public class OrderByNull extends OrderSpecifier {
public static final OrderByNull DEFAULT = new OrderByNull();
private OrderByNull() {
super(Order.ASC, NullExpression.DEFAULT, Default);
}
}
queryFactory
.select(...)
...
.orderBy(OrderByNull.DEFAULT)
.fetch();
- 정렬이 필요하더라도, 조회 결과가 100건 이하라면 애플리케이션에서 정렬한다.
- WAS 자원이 DB 자원보다 저렴하기 때문이다.
- 단 페이징일 경우, order by null을 사용하지 못한다.
커버링 인덱스
- 쿼리를 충족시키는 데 필요한 모든 컬럼을 가진 인덱스
- NoOffset 방식과 더불어 페이징 조회 성능을 향상시키는 가장 보편적인 방법
select *
from academy a
join (select id
from academy
order by id
limit 10000, 10) as temp
on temp.id = a.id;
- JPQL은 from절의 서브쿼리를 지원하지 않는다. 이 말은 즉 Querydsl도 지원하지 않는다는 말이다.
- 그렇기 때문에 커버링 인덱스 조회는 나눠서 진행한다.
List<Long> ids = queryFactory
.select(book.id)
.from(book)
.where(book.name.like(name + "%"))
.orderBy(book.id.desc())
.limit(pageSize)
.offset(pageNo * pageSize)
.fetch();
if (CollectionsUtils.isEmpty(ids)) {
return new ArrayList<>();
}
return queryFactory
.select(...)
.from(book)
.where(book.id.in(ids))
.orderBy(book.id.desc())
.fetch();
- 이렇게 하면 기존 커버링 인덱스와 거의 비슷한 성능을 보여준다.
성능개선 - Update/Insert
일괄 Update 최적화
- dirty check를 이용하여 트랜잭션 내부에 자동으로 엔티티의 변경사항을 체킹해 변경을 유도하면 수 천 건의 데이터를 처리하면 성능 이슈가 발생
- Querydsl.update를 이용하여 dirty check를 하지 말고 한 번에 처리하는 것이 성능적으로 우월
// DirtyChecking
List<Student> students = queryFactory
.selectFrom(student)
.where(student.id.loe(studentId))
.fetch();
for (Student student : students) {
students.updateName(name);
}
// Querydsl.update
queryFactory.update(student)
.where(student.id.loe(studentId))
.set(student.name, name)
.execute();
- 하이버네이트 1차 캐시와 2차 캐시가 일괄 업데이트 시 캐시 갱신이 되지 않는다.
- 업데이트 대상들에 대한 Cache Eviction이 필요하다.
- 사용 시점
- DirtyChecking : 실시간 비즈니스처리, 실시간 단 건 처리 시
- Querydsl.update : 대량의 데이터를 일괄로 Update 처리 시
JPA로 Bulk Insert는 자제한다
- JPA는 auto_increment일 때 Insert 합치기가 적용되지 않는다.
- JdbcTemplate로 Bulk Insert를 할 수 있으나 컴파일 체크, 코드-테이블 간의 불일치 체크, Type Safe 개발이 어려워진다.
TypeSafe 한 방식으로 Bulk Insert를 처리할 순 없을까?
- Querydsl != Querydsl-JPA
- Querydsl
- Querydsl-JPA -> JPQL
- Querydsl-SQL -> Native SQL
- Querydsl-MongoDB -> Mongo Query
- Querydsl-ElasticSearch -> ES Query
QClass 기반으로 Native SQL을 사용할 수 있는 Querydsl-SQL?
- 잘 사용하지 않은 이유는?
- 어노테이션을 통해 QClass를 지원하지 않기 때문에 테이블 Scan을 해서 QClass를 생성해야 하므로 상당히 번거롭다.
- 로컬 PC에 DB를 설치하고 실행
- Gradle/Maven에 로컬 DB 정보를 등록해서 flyway로 테이블을 생성
- Querydsl-SQL 플러그인으로 테이블 Scan하면 QClass를 생성
JPA 어노테이션으로 Querydsl-SQL QClass를 생성할 순 없을까?
- EntityQL를 이용
- JPA Entity를 기반으로 Querydsl-SQL QClass를 생성해준다.
// 단일 Entity
SQLInsertClause insert = sqlQueryFactory.insert(qAcademy);
for (int j = 1; j <= 1000; j++) {
insert.populate(new Academy("address", "name", EntityMapper.DEFAULT))
.addBatch();
}
insert.execute();
// OneToMany
SQLInsertClause insert = sqlQueryFactory.insert(qAcademy);
for (int j = 1; j < 1000; j++) {
Academy academy = academyRepository.save(new Academy("address", "name"));
insert.populate(new Student("student", 1, academy), EntityMapper.DEFAULT).addBatch();
insert.populate(new Student("student", 2, academy), EntityMapper.DEFAULT).addBatch();
}
insert.execute();
EntityQL - 단점
- Gradle 5 이상 필요
- 어노테이션 Column(name=””) 필수
- primitive type 사용 X, 무조건 Wrapper 클래스
- querydsl-sql이 개선되지 못해 불편한 설정
- Embedded 미지원
결론
- 상황에 따라 ORM/ 전통적 Query 방식을 골라 사용할 것
- JPA / Querydsl로 발생하는 쿼리 한번 더 확인하기