캐시(Cache)란?
자주 사용되는 데이터를 저장하는 공간을 의미한다. 이것을 왜 사용하느냐? 자주 사용되는 데이터를 매번 요청 때마다 생성하여 응답하는 것보다는 생성된 데이터를 저장해놓고 똑같은 요청이 왔을 때 로직을 거치지 않고 데이터를 반환해주는 것이 서버에 리소스 사용을 줄일 수 있으므로 성능을 향상시킬 수 있다.
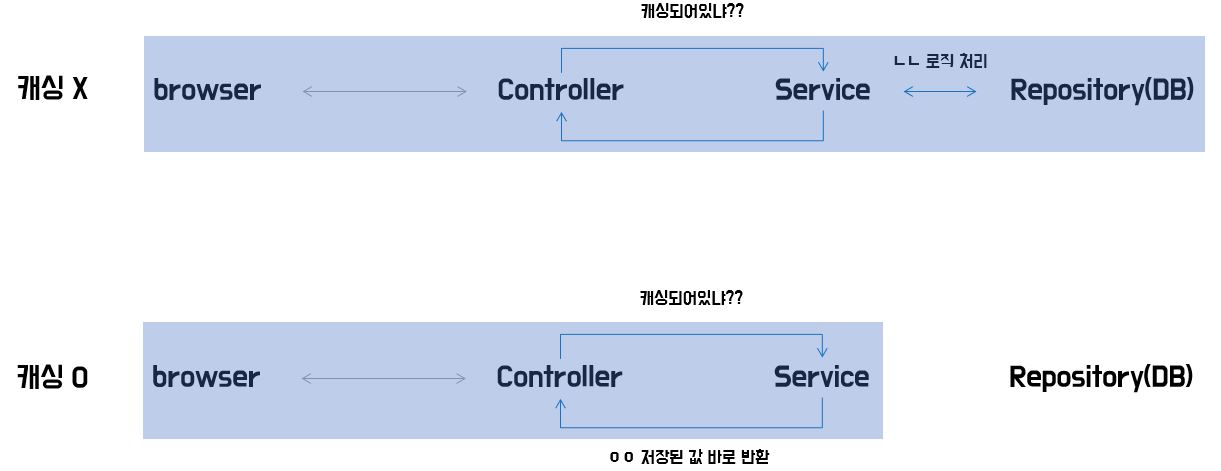
그러면 RDB에 데이터를 저장하지 않고 모두 캐싱해버리면 되지 않냐? RDB에 저장하는 데이터는 디스크(HDD, SSD)에 저장하고 캐싱하는 데이터는 메모리(RAM)에 저장하기 때문에 저장 공간에 한계가 있으므로 모두 캐싱하기에는 무리가 있기에 필요한 부분을 캐싱하여 저장 공간을 효율적으로 사용해야 한다.
그러면 캐시는 어디에 사용하면 좋을까?
- 클라이언트에게 전달되는 값이 동일하거나
- 빈번하게 호출되거나
- 한번 처리할 때 많은 서버 리소스를 요구하거나
보통 위 조건을 충족하면 고려해볼만 하다. 예로는 공지사항, 조회수, 랭킹 등이 있다.
반대로 캐시를 사용하지 않아야 될 경우는?
- 실시간으로 정확성을 요구하는 경우
- 빈번하게 데이터 변경이 일어나는 경우
실시간 동기화 vs 성능 향상은 tradeoff 관계라고 생각하면 된다.
참고로 spring-boot-starter에서 제공하는 캐시는 서버를 끌 때 데이터가 날아가기 때문에 유지하고 싶다면 redis와 같은 외부 저장소를 이용해야 한다.
실습
내가 프로젝트에서 활용했던 사례를 토대로 실습을 하려고 한다. 시나리오는 사용자 프로필을 가져와야 하는데 프로필을 가져오는 로직 처리가 한 번에 여러 쿼리문을 요구하고 빈번하게 요청을 해서 한 번 만들어진 프로필 데이터를 캐싱하여 사용하는 것이다.
의존성(Dependency)
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-cache'
}
@EnableCaching
@SpringBootApplication
@EnableCaching
public class CacheApplication {
public static void main(String[] args) {
SpringApplication.run(CacheApplication.class, args);
}
}
@Cacheable
@Cacheable(value = "userDetail", key = "#userId")
public UserDetailsDto findUserDetails(Long userId) {
로직 처리...
UserDetailsDto result = UserDetailsDto.builder()
...
.build();
return result;
}
@CachePut
@CachePut(value = "userDetail", key = "#updateUserDto.id")
public UserDetailsDto updateProfile(UpdateUserDto updateUserDto) {
로직 처리...
return UserDetailsDto.builder()
...
.build();
}
@CacheEvict
@CacheEvict(value = "userDetail", key = "#userId")
public void deleteUser(Long userId) {
로직 처리...
}
설명
@Cacheable, @CachePut, @CacheEvict 를 사용하게 되면 쉽게 캐시를 이용할 수 있다.
- @Cacheable : 캐시 생성, 전달 담당
userDetail::<userId>:UserDetailsDto메모리에 저장, 이미 캐싱되어 있다면 저장되어 있는 값 전달
- @CachePut : 캐시 내용 수정 담당
userDetail::<userId>:UserDetailsDto값 수정
- @CacheEvict : 캐시 삭제 담당
userDetail::<userId>메모리에서 삭제
어노테이션 속성
- key : 키 값의 접두사를 결정
- value : 캐싱된 값을 어떤 값으로 식별한 것인지 결정
key::value : 캐싱 데이터의 형태가 되어 예제에서는 userDetail::<userId> : UserDetailsDto 값이 저장되는 것이다.
결과
logging
@GetMapping("/{userId}")
public ResponseEntity<UserDetailsDto> getUserDetails(@PathVariable Long userId) {
long startTime = System.currentTimeMillis();
UserDetailsDto result = userService.findUserDetails(userId);
log.info("캐싱 적용 전/후 : " + (System.currentTimeMillis() - startTime) + "ms");
...
}
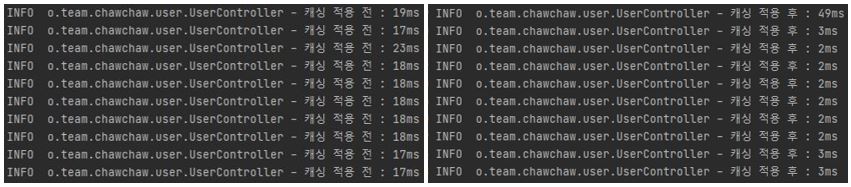
캐시가 적용되지 않았을 때는 꾸준히 20ms 정도의 latency가 발생하는 것을 확인할 수 있고 적용되었을 때는 첫 번째 캐싱하기 전 요청 이외에는 평균 2ms의 latency가 발생하는 것을 확인할 수 있다.
locust
from locust import HttpUser, task
class PerfomanceTest(HttpUser):
@task
def findUserDetail(self):
self.accessToken = 'Bearer <>'
self.headers = {'Authorization' : self.accessToken}
self.url = '/users/1'
self.client.get(url=self.url, headers=self.headers)

500명이 동시 접속하여 접근하려고 했을 때의 차이이다. 위가 캐싱 적용 전 아래가 캐싱 적용 후이다. 응답 평균 시간과 동시 초당 접속자 수를 비교해보면 두 배 가까이 차이 나는 것을 확인할 수 있는 것으로 보았을 때 성능이 확실히 개선된 것을 확인할 수 있다.