마이크로서비스 아키텍처(MSA)로 구성되어 있는 서비스들은 각자 다른 IP와 Port를 가지고 있다 이러한 서로 다른 서비스들의 IP와 Port 정보에 대해서 저장하고 관리할 필요가 있는데 이것을 Service Discovery라고 한다
왜 필요하지?
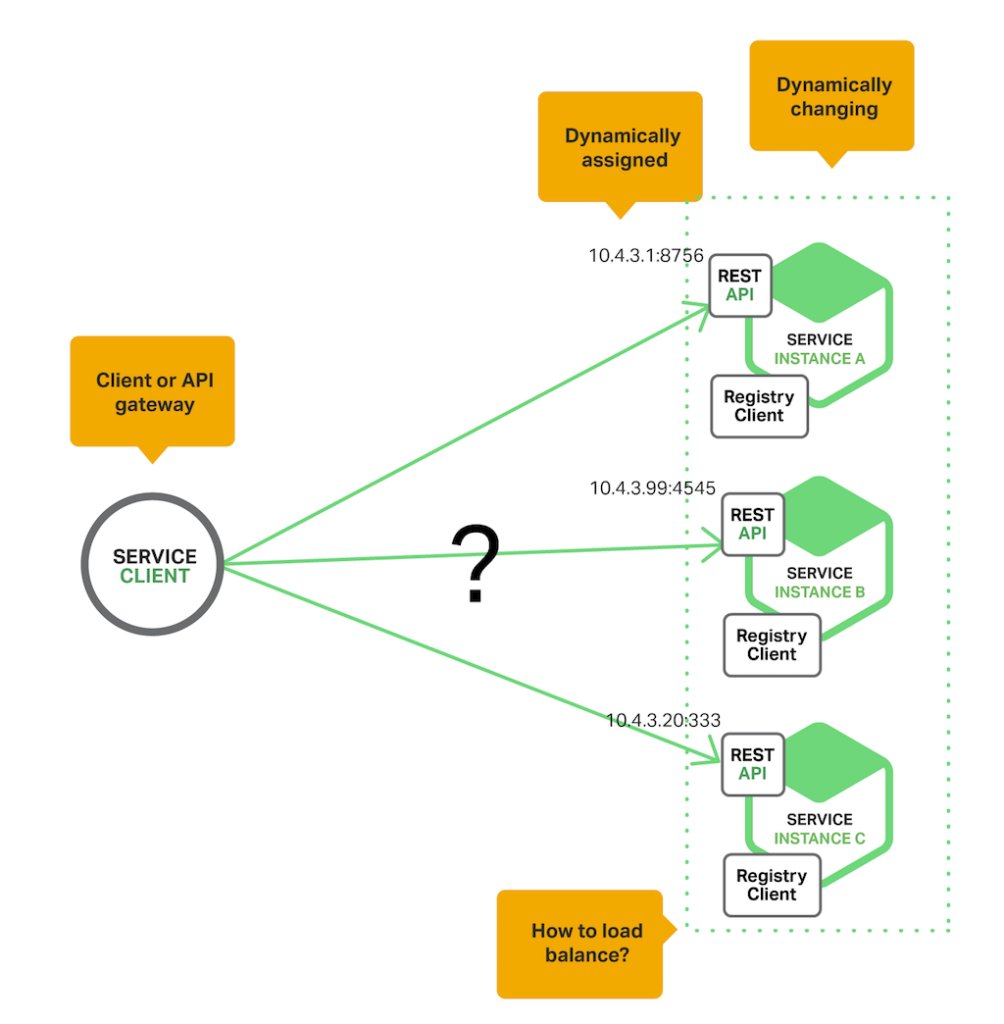
여러 서비스들을 운용하기 위해서 클라우드 환경에서 인스턴스를 생성하여 구축할 것이다 이때 클라우드 환경에서 인스턴스는 AutoScaling, 생성, 삭제, 확장 등을 거치면서 IP나 Port들이 동적으로 변경될 가능성이 많다 그러면 그때마다 서비스 변경사항에 대해서 일일이 알아내고 수정하고 하기에는 수십 ~ 수백개의 서비스들을 일일이 관리하기 어려울 뿐더러 클라이언트가 원하는 정보를 얻기 위해 요청 할 서비스를 찾기에 어려움을 겪을 것이다
AutoScaling : 사용자가 정의한 주기나 이벤트에 따라 서버를 자동으로 생성하거나 삭제하는 것을 말한다 제공하는 서비스에 대해서 사용자가 몰리거나, 여유로운 시간대에 서버를 자동으로 늘리거나 줄여 비용부담을 줄이고 원할한 서비스를 제공할 수 있다
구현 두 가지 방법
- 클라이언트 사이드 디스커버리 패턴(Client-Side Discovery pattern)
- 서버 사이드 디스커버리 패턴(Server-Side Discovery pattern)
클라이언트 사이드 디스커버리
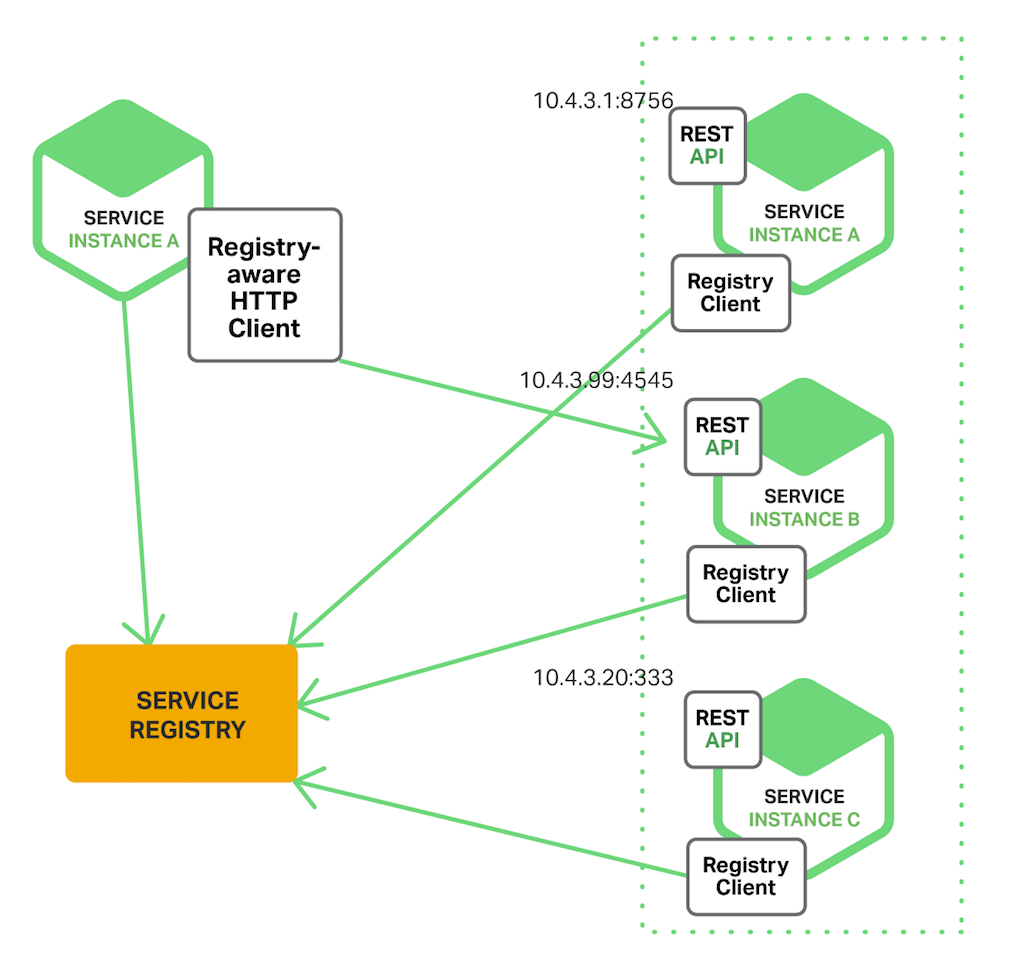
서비스 클라이언트가 Service register에서 서비스의 위치를 찾아서 호출하는 방식이다
장점
- 비교적 간단하다
- 클라이언트가 사용 가능한 서비스 인스턴스에 대해서 알고 있기 때문에 각 서비스별 로드 밸런싱 방법을 선택할 수 있다
단점
- 클라이언트와 서비스 레지스트리가 연결되어 있어서 종속적이다
- 서비스 클라이언트에서 사용하는 각 프로그래밍 언어 및 프레임 워크에 대해서 클라이언트 측 서비스 검색 로직을 구현해야 한다
대표적으로 Netflix OSS(Netflix Open Source Software)에서 Client-Side discovery Pattern을 제공하는 Netflix Eureka가 Service Registry 역할을 하는 OSS이다
Eureka에 대해서 알아보기 → 링크
서버 사이드 디스커버리
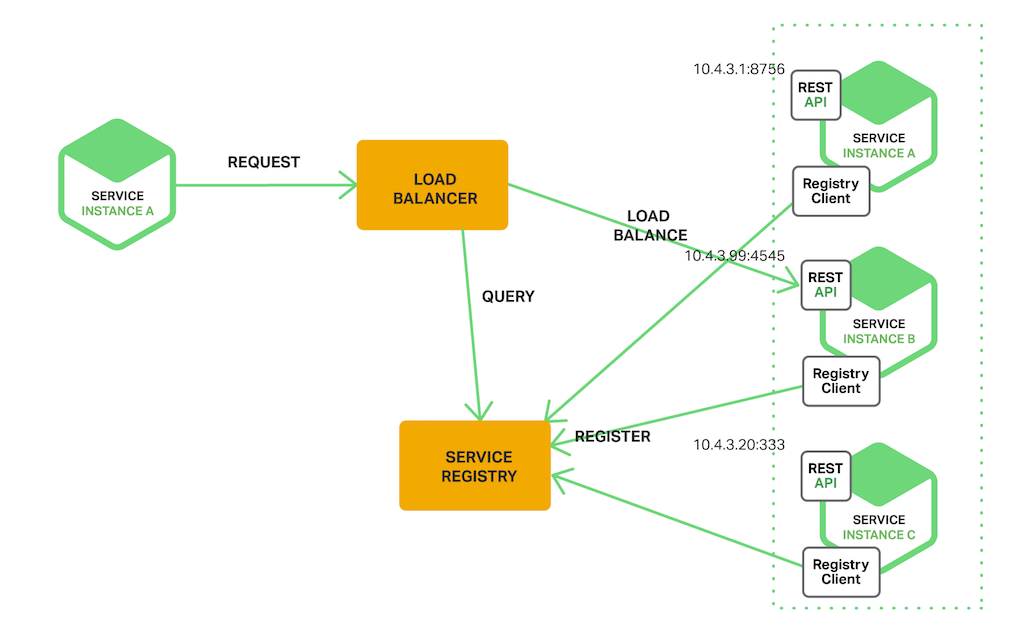
호출 되는 서비스 앞에 로드밸런서를 넣는 방식이고, 클라이언트는 로드밸런서를 호출하면 로드밸런서가 Service Register로 부터 등록된 서비스의 위치를 전달하는 방식이다
장점
- discovery의 세부 사항이 클라이언트로부터 분리되어있다(의존성 ↓)
- 분리 되어 있어 클라이언트는 단순히 로드 밸런서에 요청만 한다 따라서 각 프로그래밍 언어 및 프레임 워크에 대한 검색 로직을 구현할 필요가 없다
- 일부 배포환경에서는 이 기능을 무료로 제공한다
단점
- 로드밸런서가 배포환경에서 제공되어야 한다
- 제공되어있지 않다면 설정 및 관리해야하는 또 다른 고 가용성 시스템 구성 요소가 된다
Server-Side Discovery의 예로는 AWS Elastic Load Balancer(ELB), Kubernetes가 있다